
-Summary-
의미론적 태그, 구글 검색엔진 최적화 가이드
02-10 (의미론적 태그 ~ 검색엔진 최적화 3)

의미론적 태그는 기능은 없지만 웹을 만들 때 사용되는 구조에 의미를 부여해준다. 의미론적 태그는 생활코딩 사이트에서 캡처한 위 사진처럼 여러가지가 있다. 이중에서 header, footer, nav는 학교에서 정보처리 산업기사 수업을 할 때 구역을 구분해주는 역할로 많이 접했었다.
header는 머리라는 뜻에 걸맞게 가장 위쪽에 위치하는 것들을 의미하며, 해당 사이트 전체에 대한 정보가 들어있는 부분이다.

네이버 웹사이트로 예를 들자면 빨갛게 표시된 이 위쪽 부분이 header 부분인 것 같다. 이 위쪽에는 naver 광고가 있는데, 이부분도 header에 포함될 것 같지만 광고기 때문에 aside 부분이 아닐까 생각이든다.
nav는 navigation의 약자로 웹페이지의 컨텐츠를 탐색할 때 사용하는 부분이다.

네이버 웹사이트에서는 메일, 카페, 블로그 등 네이버의 여러 컨텐츠의 사이트로 접속할 수 있게 해주는 이 메뉴들이 nav에 해당하는 것 같다.
footer는 발이라는 뜻에 걸맞게 아래쪽에 있는 회사 정보나, copyright 문구 등이 해당된다.
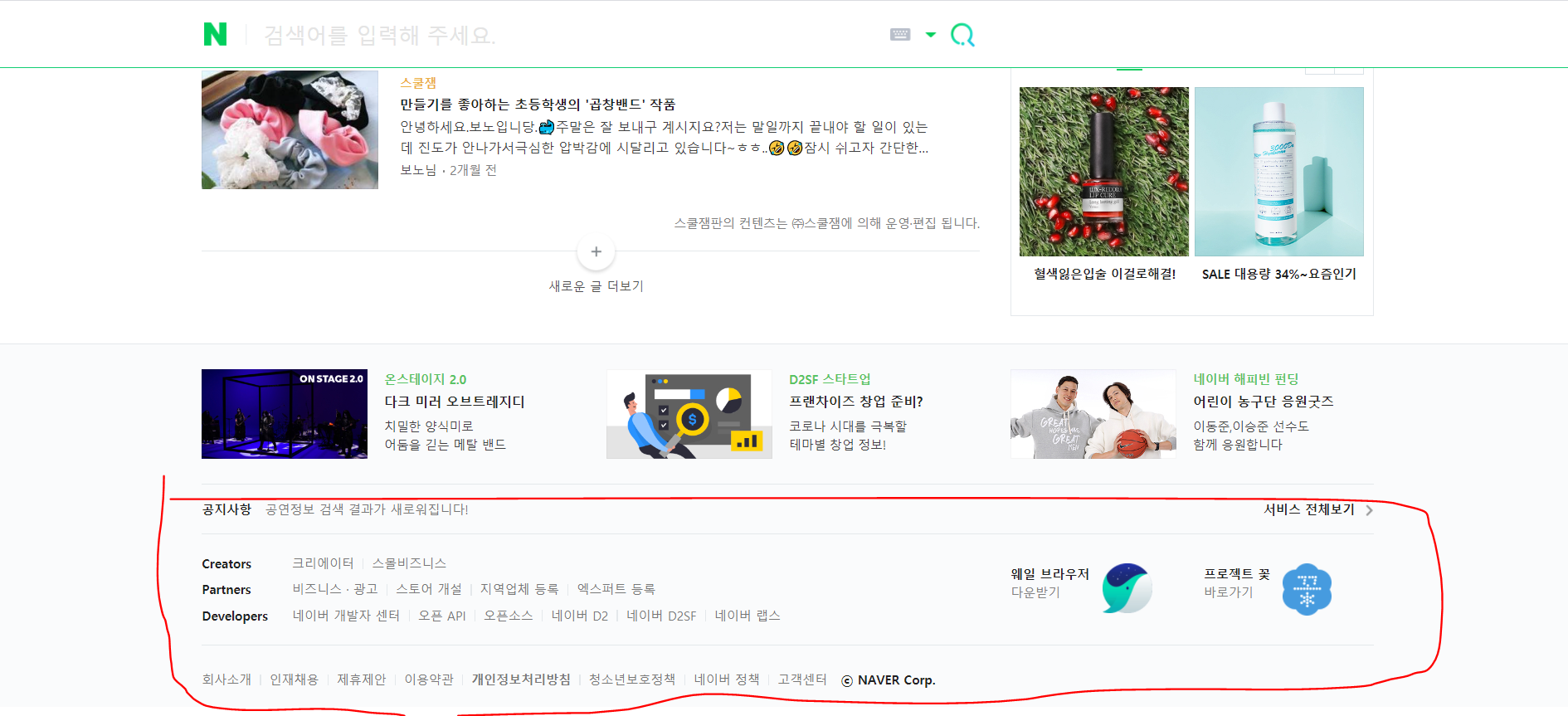
네이버에서는 표시한 부분처럼 아래쪽 회사 정보, 개인정보 처리 방침으로 접근할 수 있는 링크가 있는 부분이 footer에 해당되는 것 같다.
<body>
<h1>OO홈페이지</h1>
<ul>
<li><a href="#">페이지1</a></li>
<li><a href="#">페이지2</a></li>
<li><a href="#">페이지3</a></li>
<li><a href="#">페이지4</a></li>
<li><a href="#">페이지5</a></li>
</ul>
<h2>본문</h2>
<p>
1234567890 abcdefghijklmnopqrstuvwxyz
</p><br><br><br>
<p>OO회사 copyright free</p>
</body>의미론적 태그를 실습해보기 위해, 간단한 홈페이지 코드를 만들어 봤다.

위 사진은 위 코드를 브라우저로 열었을 때 나오는 화면을 의미론적 태그 header, nav, article, footer로 구분한 모습이다. article 같은 경우 위에 정리를 해두지 않았는데, 본문을 의미하는 태그다. nav 부분은 링크 표시가 없는데, 코드 작성 당시 실수로 a태그를 넣는 것을 잊어버리고 캡처를 해서 링크 표시가 없이 됐다.
위 사진처럼 코드를 의미론적 태그로 구분해 보겠다.
<body>
<header>
<h1>OO홈페이지</h1>
</header>
<nav>
<ul>
<li><a href="#">페이지1</a></li>
<li><a href="#">페이지2</a></li>
<li><a href="#">페이지3</a></li>
<li><a href="#">페이지4</a></li>
<li><a href="#">페이지5</a></li>
</ul>
</nav>
<article>
<h2>본문</h2>
<p>
1234567890 abcdefghijklmnopqrstuvwxyz
</p>
</article>
<br><br><br>
<footer>
<p>OO회사 copyright free</p>
</footer>
</body>먼저 h1 태그로 만들어준 제목 부분을 header로 감싸줬고, 메뉴 부분인 ul,li,a 부분은 nav로, 본문 부분은 article, 회사 정보와 copyright 부분은 footer로 감싸줬다.
<section>
<article>
본문1
</article>
<article>
본문2
</article>
<article>
본문3
</article>
</section>경우에 따라 본문이 여러개일 수도 있는데, 이럴 때는 article 태그를 여러번 써주고 section 태그로 감싸주면 된다.
이 section은 header, nav 같은 의미론적 태그에 포함된 기능인데, header 같은 경우는 웹사이트의 중요한 내용, 전체 정보를 포함하는 section, 즉 header = header section이다. nav, footer 등 역시 특정 정보를 포함하는 section의 역할을 하는 것이다.
이 section은 뭔가 특정한 역할로 묶기 애매한 부분들을 묶어준다. 맨 위의 사진에 포함되지 않는 정보들을 section을 통해 묶어주면 된다.
-검색엔진 최적화-
검색엔진 최적화(SEO)란 구글, 네이버 등과 같은 검색엔진이 웹사이트의 컨텐츠를 잘 해석할 수 있도록, 또한 사용자들이 검색했을 때 상위에 노출될 수 있도록하는 노력을 말한다.
검색엔진 최적화를 하기 위해서는 앞서 배운 header, nav 등과 같은 의미론적 태그들을 잘 쓰는 것이 기본이다.
위는 구글검색 엔진 최적화 관련 가이드가 적혀있는 pdf 파일이다. 이 pdf의 가이드에 맞춰 강의가 진행되므로, 이 pdf 관련으로 정리를 진행하겠다.
-명확하고 독창적인 title 태그 작성
검색엔진 최적화를 위해서 title 태그를 잘 작성하는 것이 좋다. <title>생활 코딩</title>과 <li>생활 코딩</li>이 작성되어 있는 각각의 사이트에서, 사용자가 생활 코딩을 검색했을 때 우선순위가 높게 노출되는 사이트는 바로 title 태그가 생활 코딩인 사이트다. 따라서 title 태그가 우선순위가 높은 만큼, 검색엔진 최적화를 하기 위해서는 title 태그를 잘 작성해야한다.
title 태그를 위한 권장 사항
- 페이지의 컨텐츠를 정확하게 설명하는 제목
- 페이지마다 고유한 title 태그 작성
- 간결하면서 내용을 포함한 제목 작성
위는 구글 검색엔진 최적화 기본 가이드의 5 페이지에 나와있는 title 태그를 위한 권장 사항이다. 당연하게도 페이지의 컨텐츠를 정확하게 설명하는 제목이어야한다. 페이지와 관련이 없는 제목이면 title을 보고 접속한 사용자에게 원하는 정보를 제공해줄 수 없기 때문에 관련 있는 제목이어야한다.(이 부분은 따로 제제가 있는지는 모르겠다.) 이건 새롭게 알게 된 사항인데, 페이지마다 고유한 title을 작성해야한다. 모든 사이트에 똑같은 title 태그로 작성한다면 검색엔진이 사이트의 분별력을 높이는데 있어 저해 요소가 될 수 있다고 한다. 마지막 사항인 간결하면서 내용을 포함한 제목 작성은 제목이 너무 길어질 경우 검색 결과의 일부분만 표시되기 때문에 간결하게 작성하는 것이 좋다고 한다.
-description meta 태그 활용
앞서 배운 meta 태그의 name="description" content="(요약)" 속성으로 페이지의 요약 정보를 검색엔진에 제공하는 것이다.
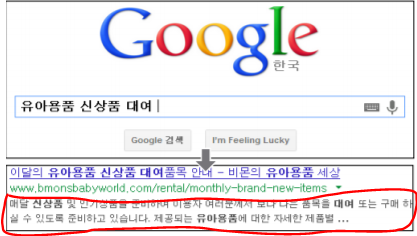
위 사진은 구글 검색엔진 최적화 기본 가이드의 6 페이지에 있는 예시 사진이다. 빨간 선으로 표시한 부분이 바로 <meta name="description" content="(요약)"> 이 meta 태그에서 content 부분이 제공하는 페이지의 요약 정보다.
이 description을 작성할 때는 1~2개의 문장이나 짧은 단락을 적는 것이 좋다.
description 태그를 위한 권장 사항
- 페이지의 내용을 정확하게 요약하기
- 각 페이지마다 내용에 맞는 고유한 설명 사용
위는 구글 검색엔진 최적화 기본 가이드의 7 페이지에 나와있는 description을 위한 권장 사항이다. 당연하지만 페이지의 내용을 정확하게 요약해야한다. 관련 없는 정보를 입력하거나, "이것은 웹페이지입니다" 같은 페이지의 일반적인 설명을 적으면 안된다. 또한 위 title 태그처럼 각 페이지에 고유한 설명을 사용하는 것이 좋다.
-페이지의 URL 구조 개선
페이지의 url은 이해하기 쉽게 단어 등을 활용하는 것이 좋다.
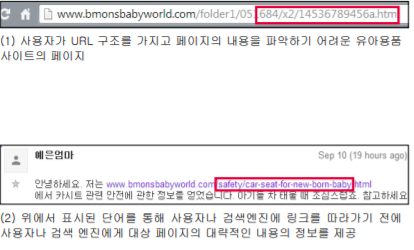
위 사진은 구글 검색엔진 최적화 기본 가이드의 8페이지에 위치한 예시 사진이다. 첫 번째 사진의 url은 숫자, 영어가 혼합돼, url을 봤을 때, 이 사이트가 어떤 사이트인지를 파악하기 힘들 반면, 두 번째 사진의 url은 url이 영어 단어로 이루어져 첫 번째 사진보다 사이트를 파악하기 훨씬 수월한 것을 알 수 있다.
이 url의 구조를 개선했을 때 얻을 수 있는 이점은 url이 검색 결과의 일부로 사용된다는 것이다.
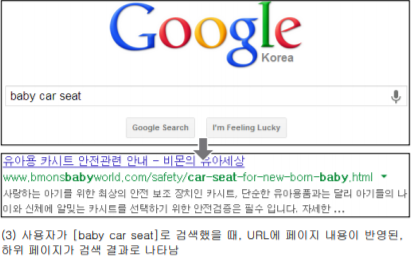
같은 페이지에 위치한 위 사진처럼, baby car seat를 검색했을 때, url에 포함된 단어만으로 검색 결과에 보여지고, 또한 해당 url에 포함된 단어가 굵게 강조되어 표시된다.
URL 구조를 위한 권장사항
- URL에 단어 사용
- 단순 디렉토리 구조 만들기
- 특정 문서에 도달하기 위한 한 가지 형태의 URL 제공
위는 구글 검색엔진 최적화 기본 가이드의 9 페이지에 나와있는 URL 구조를 위한 권장 사항이다. 앞서 봤듯이 url에 단어를 사용하는 것이 유리하다. 두 번째로 단순 디렉토리 구조 만들기라는 것이 있는데, 이는 생활 코딩에서 다루지 않은 내용이다.

위는 네이버 뉴스의 url인데 보면 '/'표시로 구분된 것을 볼 수 있다. 마치 윈도우나 리눅스 파일 경로 같은데, 이처럼 /로 구분된 것이 하나하나의 디렉토리라 볼 수 있다. 단순 디렉토리 구조를 만들라는 의미는 너무 많은 디렉토리를 중첩해서 사용하거나, 내용과 관련 없는 디렉토리 이름 사용을 안하는 것이 좋다는 것 같다. 세 번째, 특정 문서에 도달하기 위한 한 가지 형태의 URL 제공은 같은 내용의 컨텐츠(문서)가 여러 개의 url을 가질 수 있는데(예로 naver 메인 화면의 주소가 naver.com navermain.com 이런식으로 동일한 컨텐츠(문서지만) 여러개의 url이 존재할 수도 있다는 뜻이다.) 이럴 경우 해당 주소에 대한 인지도가 분산될 수 있기 때문에, 동일한 컨텐츠는 한가지 형태의 url를 사용하는 것이 좋다는 뜻이다.
한 컨텐츠를 여러 url로 접속할 경우 head의 <link rel="canonical" href="(url)">로 해주면 되는데, 이럴 경우 해당 페이지를 검색했을 때 link 태그를 보고 해당 url과 같은 페이지라 인식해, 해당 url의 페이지를 보여준다고 한다.
실습을 해보았지만 제대로 안되는 것을 보아, 검색을 했을 때만 해당되는 것 같다.
이 방법 말고 리다이렉션을 해주는 방법이 있다. 가끔 어떤 사이트를 접속할 때 redirection이라는 문구가 뜨고, 몇초 기다리면 접속하려는 사이트로 보내주는 경우가 있는데, 이 때 쓰이는 것이 바로 리다이렉션이다. 1.html로 리다이렉션이 구현된 사이트가 있다 가정할 때, 이 사이트에 접속하면 1.html로 보내주는 것이다. 이는 java, php ruby 등 서버 쪽 언어로 구현이 가능하다고 한다.
-사이트 내에서 이동하기 쉽게 만들기
검색 엔진이 사이트의 정보를 수집하는 것을 크롤링이라고 한다. 웹사이트에서 페이지의 정보를 검색 엔진이 수집할 때 하이퍼 텍스트(a 같은 링크 태그들)을 이용해서 여러 페이지의 정보들을 쭉 긁어가기 때문에, 검색 엔진 입장에서는 모든 페이지가 링크로 잘 연결되어 있어야 정보를 잘 가져갈 수 있다. 따라서 사이트 내에서 이동하기 쉽게 만들기라는 것은 다른 페이지로 이동할 수 있는 링크들이 잘 되어 있어야한다는 것을 의미한다.

위 사진은 구글 검색엔진 최적화 기본 가이드의 10페이지에 위치한 예시 사진이다. 사용자가 위치한 웹페이지가 어디고, 그 상위 웹페이지는 어디다. 이런 식으로 경로를 제공해주면 검색엔진이 정보를 수집할 때 도움이 된다 한다.
검색엔진의 관점이 아닌 사용자의 입장에서는 홈페이지의 url의 일부를 지울 수도 있는데(예를 들어 dypar.com/it/programming/html url이 있다 가정하면 가운데 부분의 it나 programming을 지우는 것) 이럴 때 404 같은 에러 페이지가 아닌, 다른 웹페이지로 이동할 수 있는 동선을 제공하는 것이 좋다.
사이트 내 쉬운 이동을 위한 권장사항
- 자연스러운 계층 구조 만들기
- 이동 경로를 위해 텍스트 링크 사용
- 사이트에 HTML 사이트맵 페이지 배치 및 XML 사이트맵 파일 사용
- 유용한 404 페이지 사용
위는 구글 검색엔진 최적화 기본 가이드의 11~12 페이지에 나와있는 사이트 내 쉬운 이동을 위한 권장 사항이다. 자연스러운 계층 구조 만들기는 당연한 사항이고, 이동 경로를 위해 텍스트 링크 사용 이부분은 앞서 실습했던 a 태그를 통한 다른 페이지 이동 등에 해당된다. 세 번째 사항은 아직 배우지 못한 내용이라 잘 모르겠다. 네 번째 사항은 url의 일부를 지우는 등을 통해 잘못된 주소에 접속했을 때, 단순 404 페이지만 띄우는게 아닌, 사용자가 올바른 페이지로 돌아갈 수 있도록 안내해주는 것이다.
02-11 (검색엔진 최적화 4 ~ 검색엔진 최적화 7)
-검색 엔진을 위한 것이 아닌 사용자를 위한 콘텐츠 작성-
위에서 의문이 들었던 내용이 이 부분에서 해소가 됐다. 정리하면서 혹시나 어그로성으로 키워드나, 요약 등을 없는 내용까지 지어내서 제공하면 어떻게 될지 의문이 들었는데, 이럴 경우 웹 스팸으로 인정되어 차단될 수 있다.
사이트는 사용자의 요구에 맞게 설계하되, 이 과정에서 검색 엔진이 엑세스하기 쉽게 만든다면 좋은 사이트가 될 수 있다. 사용자 편의를 고려하지 않고 검색 엔진만을 위한 사이트를 만들면 안된다는 것이다.
-보다 나은 앵커 텍스트 작성-
앵커 텍스트란 링크의 이름인데, 예를들어 <a href="1.html">1.html</a> 이런식으로 1.html으로 가는 링크를 작성하면 a 태그로 감싸진 이 1.html이 앵커 텍스트에 해당된다.
이 앵커 텍스트는 해당 링크의 페이지에 대한 대표성이 있는 이름을 앵커 텍스트로 지정하는 것이 좋다.
앵커 텍스트를 위한 권장 사항
- 내용을 함축하는 텍스트 선택
- 간결한 텍스트 작성
- 링크를 눈에 쉽게 포맷하기
- 내부 링크에 앵커 텍스트 활용을 고려하기
위는 구글 검색엔진 최적화 기본 가이드의 17 페이지에 나와있는 앵커 텍스트를 위한 권장 사항이다.
먼저 '페이지', '여기를 클릭' 같은 일반적인(해당 링크가 어떤 내용인지 알 수 없는) 앵커 텍스트를 쓰기보다는 해당 링크의 내용을 함축하는 텍스트를 사용해야한다. 또한 해당 링크의 url을 앵커 텍스트로 사용해서도 안된다.
당연하지만 긴 텍스트 보다는 간결한 것이 좋고, 링크는 일반 텍스트처럼 보인다면 사용자가 링크로 인식하기 힘드므로 일반적인 링크의 모습인 파란 색에 파란 줄처럼 사용자가 링크임을 알아 볼 수 있는 스타일을 적용해야한다.

위 사진이 실습에서 구현했던 링크인데, 이 링크의 스타일은 css라는 스타일 문법을 사용한다면 바꿀 수 있다.
<style>
a{
text-decoration: none;
color: black;
}
</style>
<ul>
<li><a href="movie.html">영화</a></li>
<li><a href="music.html">뮤직</a></li>
<li><a href="mail.html">메일</a></li>
<li><a href="index.html">홈으로</a></li>
</ul>
위 style 태그 안의 코드는 css 코드다.
a{
} 이 부분은 a 태그를 해당하고, text-decoration은 텍스트 꾸밈 관련인데, none을 준다면 밑줄을 없앨 수 있다. color는 말 그대로 텍스트의 색으로 기본 텍스트와 똑같이 보이도록 black을 줬다.
결과 화면을 보면 링크가 일반 텍스트와 다름없이 보이는 것을 볼 수 있다. 이 점을 주의해야한다는 것이다. 이렇게 일반 텍스트와 똑같이 보이면, 사용자가 링크를 인식할 수 없으므로, 사용자가 한눈에 링크임을 알아볼 수 있는 스타일을 적용해줘야한다.
-이미지 사용의 최적화-
앞서 img 태그를 배울 때 alt 속성에 관해서 정리했었다. 이 alt 속성은 이미지 경로 잘못됨 등의 문제가 일어나 이미지를 불러올 수 없을 때, 대신해서 나오는 텍스트인데, 이 속성을 이용해서 이미지를 최적화 시킬 수 있다. 예를들어 사용자가 이미지를 지원하지 않는 브라우저나 스크린 리더와 같은 다른 기기를 사용해서 접속한 경우 alt 텍스트를 대신 보여줄 수 있고, 또한 구글 이미지검색에서 이미지를 검색할 때 alt 속성의 텍스트를 기반으로 검색하기 때문에 써주는 것이 최적화에 도움이 된다.
또한 지난 img 태그 실습에서는 이미지와 html 파일을 같은 폴더에 두고 불러오는 식으로 실습하였는데, 이미지 폴더를 하나 만들고 그 안을 경로로 하여 이미지를 불러오는 것이 좋다. 현업에서는 보통 images 라는 폴더에 이미지들을 넣는 다고 한다.
이미지 사용을 위한 권장 사항
- 간결하면서도 설명적인 파일 이름과 alt 텍스트의 활용
- 이미지를 링크로 사용할 때 alt 텍스트를 제공하기
- 이미지 사이트맵 제공하기
위는 구글 검색엔진 최적화 기본 가이드의 19 페이지에 나와있는 사이트 내 쉬운 이동을 위한 권장 사항이다. 파일 이름과 대체 텍스트(alt)는 간결하게 작성하는 것이 좋다 한다. 이미지를 링크를 사용할 경우 alt로 대체 텍스트를 넣어주면 a 태그의 앵커 텍스트처럼, 해당 링크의 페이지에 대해 검색 엔진이 더 잘 이해할 수 있다.
-제목 태그의 적절한 활용-
제목 태그는 앞서 정리했던 h1, h2, h3 같은 태그를 말한다. 이 제목 태그를 잘 쓴다면, 해당 웹페이지가 검색엔진에 노출되는 가능성을 높여주기 때문에 중요하다. 다만 한 페이지안에 제목 태그가 너무 많으면, 사용자가 중요한 컨텐츠를 파악하기 힘들어진다.
-robots.txt를 효과적으로 활용하기-
웹사이트에는 크롤링을 위한 검색엔진의 로봇(물리적 로봇이 아닌, 네트워크를 통해 접근하는 소프트웨어를 뜻한다.) 등 많이 로봇들이 접속한다. 이 로봇들의 접속 허용 여부 정보를 담고 있는 것이 바로 robots.txt다. 이 robots.txt로 사이트 자체를 크롤링을 허용하지 않아, 검색 결과에 노출하지 않을 수도 있고, 특정 사이트만 크롤링을 금지시킬 수 있다. 방법은 나오지 않았지만 User-agent : (로봇 대상, *일 경우 모두에 해당), Disallow: (크롤링을 허용하지 않는 사이트), allow : (크롤링 허용 사이트) 이렇게 사용하는 것 같다.
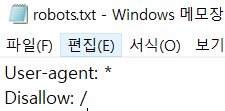
위 사진은 네이버 robots.txt다. User-agent에 *이 적혀있는데, 이는 모든 로봇을 뜻한다. Disallow는 허용되지 않다. 라는 뜻인데 여기서는 크롤링이 허용되지 않는 부분들을 말한다. 이 Disallow에 /이 적혀 있는데, 이는 naver 하위의 모든 문서(디렉토리), 즉 컨텐츠들을 크롤링 할 수 없다는 것이다. 실제로 구글에서 네이버를 검색해보면, 네이버 홈페이지를 제외한 다른 컨텐츠들은 구글에서 노출되지 않는 것을 알 수 있다.

위 사진은 dypar-tistory.com의 robots.txt, 즉 이 블로그의 robots.txt다. 호기심에 확인해봤는데, 따로 제작을 하지 않아도 자동으로 생성되는 것 같다. 보면 owner,manage, admin 등의 페이지를 제외한 나머지 페이지들은 모두 크롤링이 허용된 것을 알 수 있다. 크롤링이 허용되지 않는 사이트는 관리자 페이지 같이 민감한 정보가 있을 수 있는 페이지인 것 같다.
robots.txt를 배우면서 생각난 사실인데, 실제로 robots.txt에 disallow를 제대로 써주지 않아 구글에 사이트의 관리자 페이지가 노출돼 개인정보가 유출된 사건이 있었던 걸로 알고 있다. 공격자는 해킹을 제대로 모르던 일반인이었고, 단순히 구글 검색 명령어인 site 등을 사용해 관리자 페이지를 찾아냈다고 한다. 이처럼 보안은 robots.txt 같이 정말 기초적인 부분 하나라도 실수가 있다면, 큰 위험을 초래하는 것 같다.
robots.txt 권장사항
- robots.txt를 보안 도구로 사용하지 않기
- 민감한 콘텐츠는 보다 안전한 방법 사용하기
- 웹마스터를 위한 무료 도구 사용하기
위는 구글 검색엔진 최적화 기본 가이드의 21 페이지에 나와있는 robots.txt 권장 사항이다.
먼저 robots.txt는 보안 기법이 아니라 정상적인 검색 엔진(구글, 네이버, 다음 등등)을 차단하기 위해 사용하는 것이므로, 악의적 목적을 지닌 크래커라면 이를 따르지 않을 수 있다.(사실상 robots.txt는 그냥 txt 파일일 뿐이라, 무시하면 끝이다.) 따라서 robots.txt를 보안적으로 의존하면 안된다는 것 같다. 두 번째 사항 역시 첫 번째 사항과 비슷한데, 아무리 민감한 사이트(관리자 사이트 등)를 robots.txt를 통해 막아둬도, 무시가 가능하기에 다른 보안 방법책을 사용해야한다. 또한 오히려 robots.txt를 통해 민감한 사이트를 공격자가 알 수 있게 되므로, 허점을 드러낼 수도 있다.
-sitemap-
sitemap은 이름 그대로 웹 사이트의 지도다. 검색 엔진의 로봇들이 크롤링을 할 때, 그 사이트의 링크를 통해서 크롤링을 한다고 했는데, 매우 크거나 복잡한 사이트의 경우, 크롤링 속도가 저하되고 페이지 몇개를 빼먹을 수도 있다. 이 sitemap을 써준다면, 검색엔진 로봇들이 사이트의 크롤링 범위도 파악 가능하고, 크롤링 속도도 개선할 수 있다.
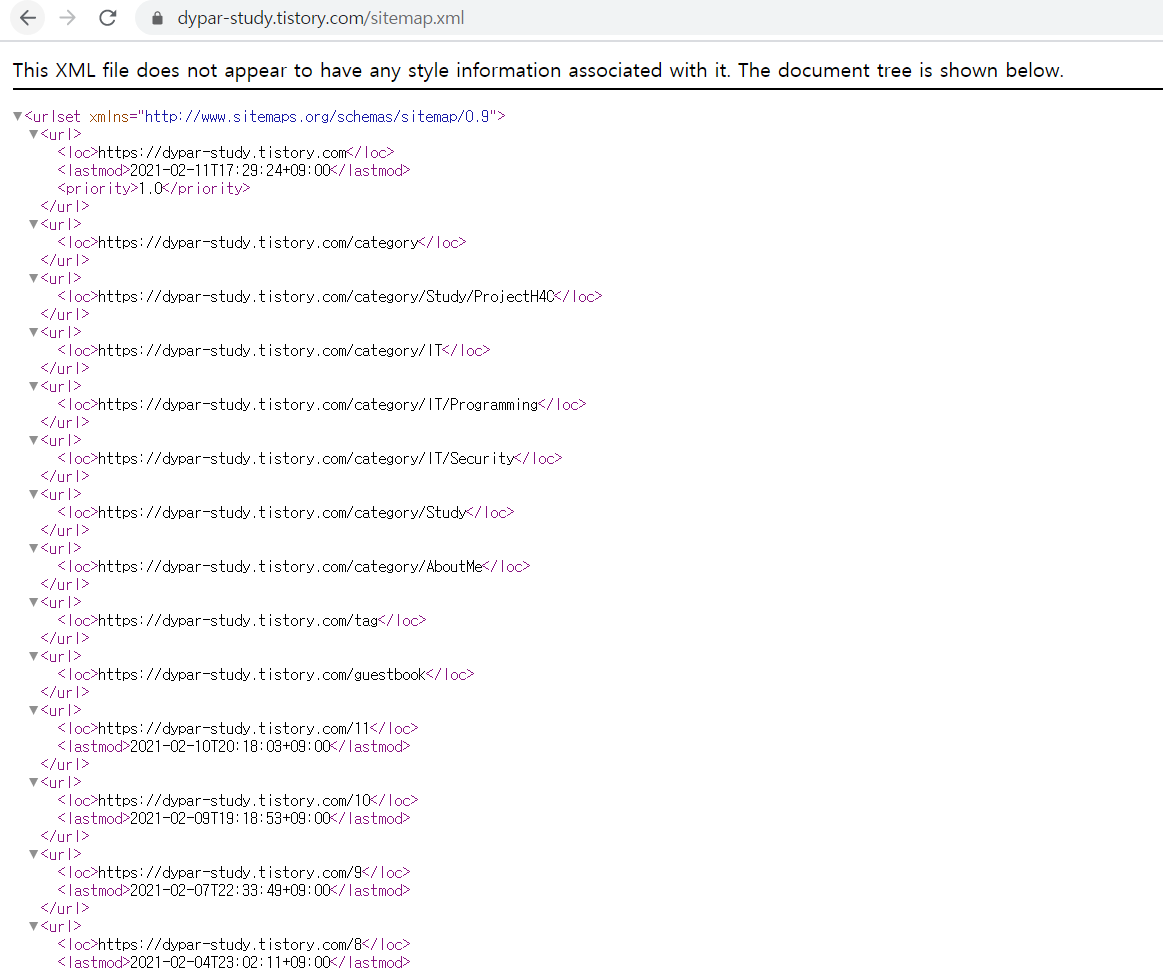
이 블로그에도 역시 sitemap이 존재했는데, 보면 지금까지 만든 카테고리, 글, 태그, 방명록 등 이 블로그에 존재하는 대부분의 페이지(관리자 페이지 들은 제외)들의 url이 xml 형태로 들어가 있는 것을 볼 수 있다.
물론 이 sitemap이 없더라도 검색엔진이 알아서 크롤링이 가능하지만, 검색엔진 로봇들의 동작을 제어하거나, 속도 개선 등이 필요하다면, sitemap을 써주면 검색엔진 최적화에 좋을 것 같다. (참고 : 구글 developer - 사이트 맵 알아보기)
-페이지 랭크-
구글에서 검색을 했을 때, 검색 결과의 순서는 페이지의 랭킹에 따라 달라지는데, 이 페이지의 랭킹을 정하는 알고리즘이 바로 페이지 랭크다.

위 사진은 생활코딩 검색엔진 최적화 7 영상에 등장하는 페이지 랭크 기본 원리 사진이다. 위처럼 c, d, e라는 사이트가 사이트 A를 링크한다면 구글은 A라는 사이트의 페이지 랭크를 높인다. 반면 B라는 사이트는 어떤 사이트에서 링크도 없기 때문에, A,B 두 사이트에 존재하는 같은 단어를 검색한다 가정할 때, 페이지 랭크가 더 높은 A라는 사이트를 B보다 먼저 보여주는 것이다. 이렇게 되면 당연하게도, B보다는 A에 사용자들이 모일 확률이 높아지게 되는 것이다. 이게 페이지 랭크의 기본적인 원리다.

또한 위 사진처럼 여러 개의 사이트가 링크하고 있는 사이트 A가 링크하는 사이트 D는 페이지 랭크가 높게 올라간다.
이 페이지 랭크의 파트를 보며 궁금증 하나가 해소 됐는데, 가끔가다 사이트의 댓글 등을 보면, 아무 의미 없는 사이트, 낚는 사이트 등의 링크를 달아져 잇는 것을 볼 수 있다. 예전에는 단순 낚아서 광고로 수익을 보는 사이트인줄 알고 있었지만, 이 역시 페이지 랭크를 높이기 위한 것일 수도 있을 것 같다.
여러 개의 사이트에 링크 -> 페이지 랭크 ↑ -> 사람들의 유입 ↑
이런식으로 사람들의 유입을 많아지게 해 여러 금전적인 이득을 볼 수도 있어 스팸이 더욱 기승을 부리는 것이다.
'Old (2021.01 ~ 2021.12) > Programming' 카테고리의 다른 글
| c언어 코딩도장 Unit 1 ~ 11 (0) | 2021.02.16 |
|---|---|
| 파이썬 코딩도장 Unit 38, 39, 43 (0) | 2021.02.14 |
| 생활코딩 HTML 버튼 ~ meta (0) | 2021.02.09 |
| 생활코딩 HTML 기술소개 ~ 선택 (0) | 2021.02.07 |
| 파이썬 코딩도장 Unit 27 ~ 37 (0) | 2021.01.31 |